
概要
今回は、PythonでPDFからテキストデータを取得する方法について説明します。
PDFの請求書等、PDFから自動でデータを取得できると便利な場合って結構ありますよね。
そんなことが簡単に出来るようになります。
そして、そのためにPDFでの文字列の座標が必要になるのですが
それを取得するためのコードもご紹介します。
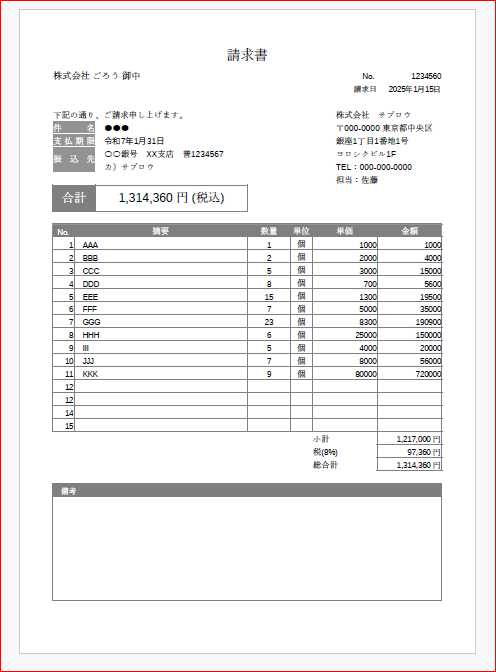
デモ用ファイル
デモ用のPDFファイルです。
今回の説明で使用しています。
ダウンロードして使ってください。
請求書用のPDFを想定しているのでパスワードを掛けて印刷などが出来ない設定になっています。
パスワードは、”1111″です。
インストール
インストールするライブラリは、以下の通りです。
pip install pyqt6 pip install pymupdf
PDFの座標について
本来の座標は、左下が(0,0)で原点になっています。
x座標は、左から右へ大きくなり、
y座標は、下から上へ大きくなります。
ところが今回使用する PyMuPDF は、左上が原点で
x座標が左か右へ大きくなり、
y座標が上から下へ大きくなります。
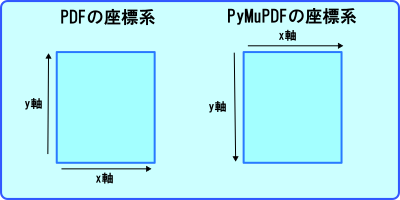
この解説では、PuMuPDFを使っているので左上減の座標系で説明しています。
取得するデータ
本来、請求書の場合に取得したいデータは
伝票番号、日付、差出人名、表の中の適用と金額などです。
ただ、今回はデモなので右上の差出人の情報と表の中から金額を1ヶ所だけ取得してみます。
うまく行かない方法
ページのデータを丸ごと取得する方法や表として取り込む方法などもありますが
実際にやってみるとあまりうまく行きませんでした。
インデックスを作るなどアバウトなデータの取得なら良いのですが
請求書などは、確実性が求められるものには向かないようです。
ですのでほしいデータの場所を矩形で指定して、その中のデータを取得するのがよさそうです。
また、表などの左詰めの文字列の場合表の罫線などの情報からx軸の最小の位置を推測する必要があります。
矩形内のデータを取得する方法
取得場所
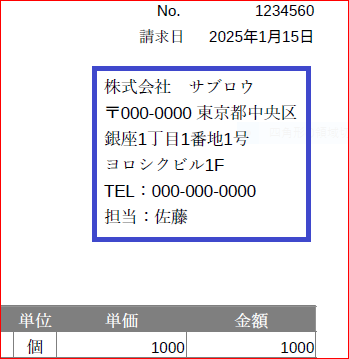
上の画像の青枠内の情報を取得します。
(x1=400, y1=120, x2=550, y2=260)内の矩形領域の情報を取得すればよいので以下のコードで
取得します。
コード
import fitz
def extract_sorted_text_from_rect(pdf_path, page_number, rect_coords):
"""
指定したPDFのページと矩形から、上下関係を正しくしたテキストを取得する。
Parameters:
- pdf_path (str): PDFファイルのパス
- page_number (int): 対象のページ番号(0始まり)
- rect_coords (tuple): 矩形の座標 (x1, y1, x2, y2)
Returns:
- str: 矩形内の文字列(上下関係を考慮)
"""
try:
with fitz.open(pdf_path) as pdf:
# 対象ページを取得
page = pdf[page_number]
# 矩形を定義
rect = fitz.Rect(*rect_coords)
# 矩形内の単語を取得
words = page.get_text("words", clip=rect)
# y座標(昇順)でソート
sorted_words = sorted(words, key=lambda w: w[1])
# 単語を結合
extracted_text = " \n".join(word[4] for word in sorted_words)
return extracted_text
except Exception as e:
print(f"Error extracting text: {e}")
return None
# 使用例
pdf_path = "請求書デモ.pdf" # PDFファイルのパス
page_number = 0 # 1ページ目
rect_coords = (400, 120, 550, 260) # 指定範囲
text = extract_sorted_text_from_rect(pdf_path, page_number, rect_coords)
print(f"Extracted Text: {text}")
コード解説
矩形領域 (x1=400, y1=120, x2=550, y=260) に囲まれた部分の文字列を取得しています。
行ごとに取得される文字列の順序が入れ替わる場合があります。
それはPDFを作ったときの文字列を入力した順序や文章の構造に依ります。
ですので必要があればy座標などの順序でソートする必要があります。
水平方向の順序が重要であればx軸でソートします。
ここからコードごとに説明します。
# 矩形を定義 rect = fitz.Rect(*rect_coords)
受け取った*rect_cords(矩形領域)をアンパックします。
fitz.Rect(400, 120, 550, 260) とするのと同等です。
アンパックしないと fits.Rect((400, 120, 550, 260)) となってしまいエラーになります。
# y座標(昇順)でソート sorted_words = sorted(words, key=lambda w: w[1]
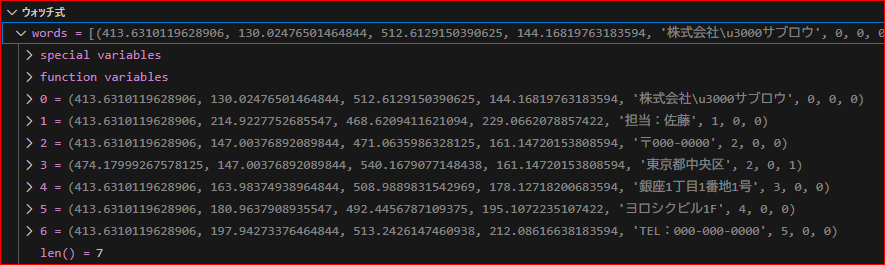
wordsの中身は、上の画像の通りです。
words[n]は、(x1, y1, x2, y2, “文字列”, ブロック番号, ライン番号, ワード番号) となっています。
keyは、words[n] を
lambda w: w[1]
に与えたときの返り値を基準に並べ替えるという事です。
つまりwordsの中身の文字列の座標の2番目の引数、y1で並び変えるという事になります。
矩形の座標
これで指定した場所のテキストが取得できるようになりました。
あとは、矩形領域の座標をどのように調べればいいのかという事です。
色々な方法が考えられますがPDFのコピーを作って、
コードで矩形を重ねて書き入れて調べれば実現は可能です。
ただ、ちょっと面倒ですね。
ですので簡易なツールを作ってみました。
座標調査ツール
PDFの表示に重ねて、指定の座標で図形を書き込むツールです。
このことによって、必要な座標を取得します。
印刷不可、コピー不可のPDFであっても読み取った情報から新たにPDFを作って描画しているので
対応できるはずです。
おおざっぱに作ってあるので対応できないこともありますがコードがあるので
創意工夫で乗り切ってください。
例えば1ページ目固定で使うツールになっていますがコードを少しいじれば2ページ目以降にも対応できるはずです。
使い方
コードを実行してPDFファイルを選択してください。
左ペインにPDFが表示されます。
右ペインの上部にPDFのサイズが表示されます。
サイズの単位は pt です。
座標の原点は、PyMuPDFを使っているので左上です。
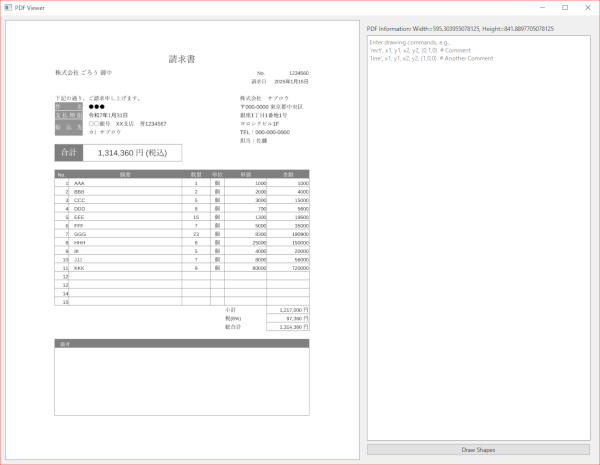
ツール実行画面
右ペインのテキストボックスに
'rect', 100, 100, 200, 200, (0, 1, 0) # これは緑の矩形です
と書いて下方の Draw Shapes ボタンを押すと緑の矩形が描かれます。
'line', 100, 100, 200, 200, (1, 0, 0) #これは赤色の直線です
- ‘line or rect’, x1, y1, x2, y2, (r, g, b)
と書きます。
最初の項目は直線か矩形を選びます
始点と終点を指定します
(r,g,b)は色指定で最大値が1です
全ての数値項目は、小数点が使えます - 一行に1図形書くことができます
- “#”以降は、コメントアウトです
コード
import io
import sys
from pathlib import Path
from PyQt6.QtWidgets import QApplication, QFileDialog, QMainWindow, \
QGraphicsView, QGraphicsScene, QMessageBox, QTextEdit, \
QSplitter, QWidget, QVBoxLayout, QPushButton, QLabel
from PyQt6.QtGui import QImage, QPixmap
import fitz # PyMuPDF
class PDFViewer(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("PDF Viewer")
self.setGeometry(500, 50, 1200, 900)
# メインウィジェットとレイアウトを作成
central_widget = QWidget(self)
self.setCentralWidget(central_widget)
layout = QVBoxLayout(central_widget)
# QSplitterを作成
splitter = QSplitter(self)
layout.addWidget(splitter)
# 左ペイン: PDF表示用のQGraphicsView
self.graphics_view = QGraphicsView(splitter)
self.scene = QGraphicsScene()
self.graphics_view.setScene(self.scene)
# 右ペイン: テキストボックス、ラベル、ボタン
right_pane = QWidget(splitter)
right_layout = QVBoxLayout(right_pane)
# 情報表示用ラベル
self.info_label = QLabel("PDF Information: Not loaded", right_pane)
right_layout.addWidget(self.info_label)
# テキストボックス
self.text_box = QTextEdit(right_pane)
self.text_box.setPlaceholderText("Enter drawing commands, e.g., \n'rect', \
x1, y1, x2, y2, (0,1,0) # Comment\n'line', x1, y1, x2, y2, \
(1,0,0) # Another Comment")
right_layout.addWidget(self.text_box)
# ボタン
self.button = QPushButton("Draw Shapes", right_pane)
self.button.clicked.connect(self.draw_shapes)
right_layout.addWidget(self.button)
# PDF関連
self.pdf_document = None
self.original_pdf_data = None # 最初に読み込んだPDFのデータを保持
# PDFを開く
self.open_pdf_file()
def open_pdf_file(self):
file_path, _ = QFileDialog.getOpenFileName(
self,
"Select a PDF file",
"",
"PDF Files (*.pdf)"
)
if file_path:
try:
# ファイルパスを正規化して読み込み
normalized_path = Path(file_path).resolve(strict=True)
# PDFをメモリに保存して最初の状態を保持
with fitz.open(str(normalized_path)) as src_pdf:
self.original_pdf_data = io.BytesIO()
src_pdf.save(self.original_pdf_data)
self.original_pdf_data.seek(0)
# メモリからPDFを読み込む
self.pdf_document = fitz.open("pdf", self.original_pdf_data.getvalue())
# PDF情報をラベルに表示
page_rect = self.pdf_document[0].rect
self.info_label.setText(f"PDF Information: Width={page_rect.width}, \
Height={page_rect.height}")
self.render_pdf()
except Exception as e:
QMessageBox.critical(self, "Error", f"Failed to load PDF: {e}")
self.close()
else:
QMessageBox.information(self, "No File", "No file was selected.")
self.close()
def render_pdf(self):
if not self.pdf_document:
return
# 最初のページを取得
pdf_page = self.pdf_document[0]
# ページを画像としてレンダリング
pix = pdf_page.get_pixmap()
image = QImage(pix.samples, pix.width, pix.height, pix.stride, \
QImage.Format.Format_RGB888)
pixmap = QPixmap.fromImage(image)
# QGraphicsSceneに画像を追加
self.scene.clear()
self.scene.addPixmap(pixmap)
self.graphics_view.setScene(self.scene)
def parse_commands(self, text):
"""
テキストボックスの内容をコマンドリストに変換し、検証する。
"""
try:
lines = text.strip().splitlines()
commands = []
for line in lines:
# コメント部分を除去
line = line.split('#')[0].strip()
if not line:
continue # 空行やコメントのみの行をスキップ
cmd = eval(f"[{line}]")
if not isinstance(cmd, list) or len(cmd) < 6:
raise ValueError(f"Invalid command format: {cmd}")
command_type = cmd[0]
if command_type not in ('rect', 'line'):
raise ValueError(f"Unsupported command type: {command_type}")
if len(cmd) != 6 or not all(isinstance(c, (int, float)) \
for c in cmd[1:5]) or not isinstance(cmd[5], tuple) or len(cmd[5]) != 3:
raise ValueError(f"Invalid format for {command_type}: {cmd}")
commands.append(cmd)
return commands
except Exception as e:
raise ValueError(f"Failed to parse commands: {e}")
def draw_shapes(self):
if not self.original_pdf_data:
QMessageBox.warning(self, "Error", "No PDF loaded.")
return
try:
# テキストボックスからコマンドデータを取得し、検証
commands = self.parse_commands(self.text_box.toPlainText())
# 元のPDFデータからドキュメントを作成
temp_pdf = fitz.open("pdf", self.original_pdf_data.getvalue())
updated_pdf = io.BytesIO() # 描画後のPDFを保持するバッファ
with temp_pdf as pdf_document:
pdf_page = pdf_document[0]
# 図形の描画
for cmd in commands:
command_type, x1, y1, x2, y2, color = cmd
shape = pdf_page.new_shape()
if command_type == 'rect':
shape.draw_rect(fitz.Rect(x1, y1, x2, y2))
elif command_type == 'line':
shape.draw_line((x1, y1), (x2, y2))
shape.finish(color=color, fill=None, width=1)
shape.commit()
# 描画後のデータをメモリに保存
pdf_document.save(updated_pdf)
updated_pdf.seek(0)
# 再レンダリングのために新たに `self.pdf_document` をロード
self.pdf_document = fitz.open("pdf", updated_pdf.getvalue())
self.render_pdf()
except Exception as e:
QMessageBox.critical(self, "Error", f"Failed to draw shapes: {e}")
if __name__ == "__main__":
app = QApplication(sys.argv)
viewer = PDFViewer()
viewer.show()
sys.exit(app.exec())
表から数値を取得する
早速ツールで 摘要が”GGG”である商品の金額を取得してみましょう。
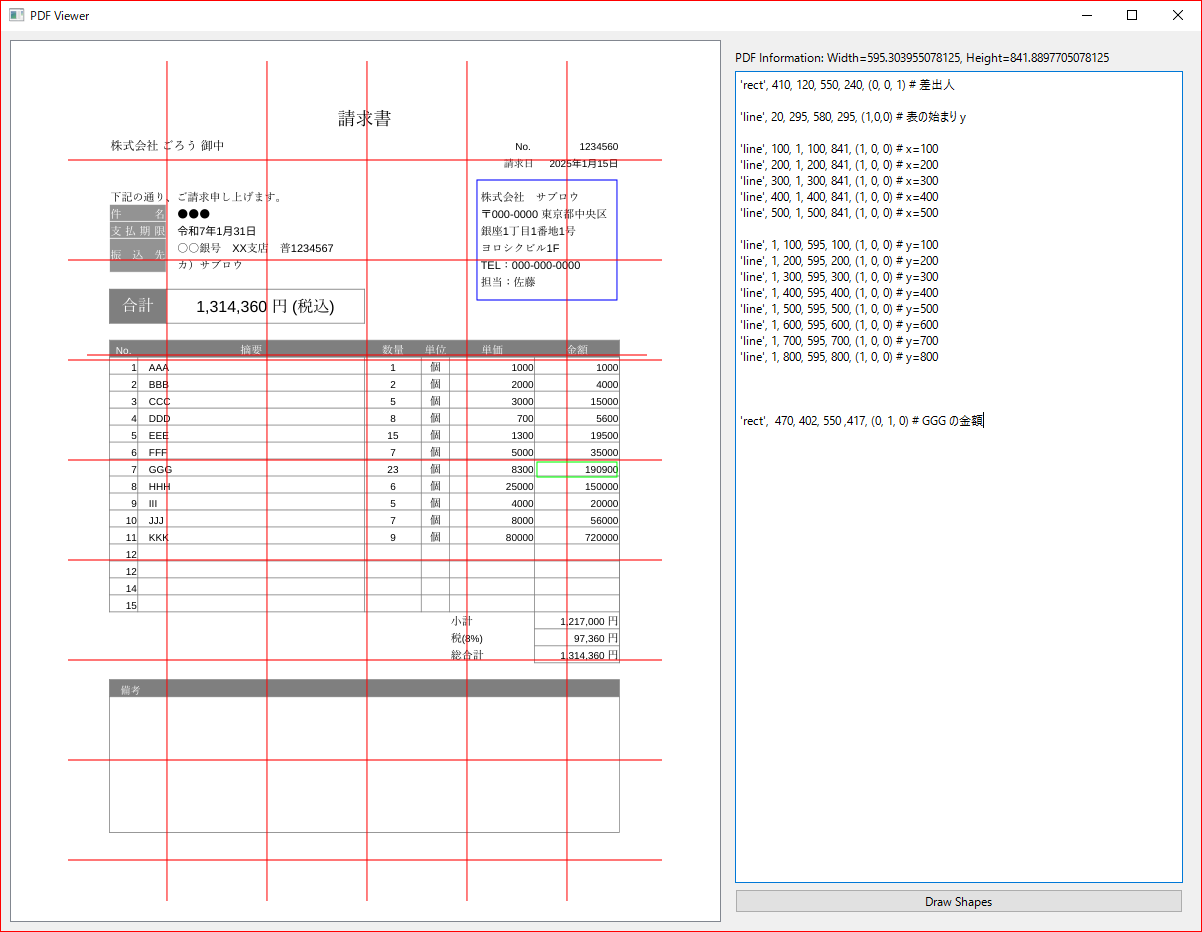
画像の緑色の矩形の部分が取得したい数字です。
'rect', 470, 402, 550 ,417, (0, 1, 0) # GGG の金額
このコマンドで描かれているので 必要な座標が分かります。
数値の場合左詰めなので、この場合は表のセルいっぱいに矩形を広げています。
小さめに設定すると文字列が欠ける場合があるので気を付けなければなりません。
また、100ptごとなどに補助線を入れると座標を設定しやすいですね。
それでは、先ほど差出人を取得したコードの座標を書き換えて
データを取得してみましょう。
“190900”と表示できましたか?
うまくできたでしょうか。
まとめ
今回は、PDFからPyMuPDFを使って文字列を取得する方法を解説しました。
その中でも実務で使えるよう、なるべく正確に文字列が取得できるように
領域で区切って取得する方法と
複数行を取得した場合、文字列の順番が入れ替わることがあるので
それをソートする方法を説明しました。
また、取得すべき領域を調査するためのコードを紹介しました。
そして、そのコードを使って表中の数値を取得しました。
これで、PDFからデータを取得したり集計する方法を説明しました。
実務に合わせてご活用ください。
次回は、PDFを生成する方法について解説する予定です。
お楽しみに!


Commnts